
Implement Resolution‑First Automated Workflows for Billing & Collections
Implementing resolution-first automated workflows for billing and collections can streamline processes by completing tasks directly within messages. This reduces friction, cuts costs, and improves metrics like resolution rate and writeback success.
Most billing and collections teams send more messages when outcomes stall. Resolution first automated workflows take a different path: they finish the task inside the message and write results back to core systems automatically. We will walk you through why this beats channel volume and how to design it safely in a regulated environment.
You are careful with change for good reasons. Systems are old, compliance is strict, and failed pilots cost trust. We respect that. This guide focuses on clarity and control: define the writeback first, reduce last‑mile friction, and prove the pilot with metrics that show real movement in cost and cycle time.
Key Takeaways:
Define completion first, then design copy and UI to serve a guaranteed, auditable writeback.
Measure resolution rate, time to resolution, writeback success, and deflection, not handle time or send volume.
Remove last‑mile friction with in‑message self‑service so customers act without logins or downloads.
Use idempotency keys, retries with backoff, and circuit breakers to stop duplicate posts and silent errors.
Start with one high‑volume, policy‑bound workflow, then scale based on proven deflection and unit‑cost impact.
Managed integration reduces risk by owning adapters, auth, schema mapping, telemetry, and writeback guarantees.
Why resolution first automated workflows beat message first tactics
Resolution first automated workflows win because they remove last‑mile friction and complete tasks inside the message. That single change reduces handoffs, lowers unit cost, and speeds cycle times. The proof shows up in four metrics: completion rate, time to resolution, writeback success, and deflection.
Conversations are not outcomes
More channels and more reminders do not fix a broken last mile. If customers must jump to a portal, wait for an agent, or repeat identity checks, completion drops. You add effort on both sides, and work fragments across tools. The unit cost rises while vanity counts make things look busy.
Define success by resolution rate, not contact volume. A message that ends in a verified payment, a compliant plan, or a captured attestation is the outcome. Anything short of that creates parallel queues and manual wrap‑up. We have seen careful teams chase containment targets while backlogs and bad debt still grow. The pattern is familiar and avoidable.
When outcomes write back to the system of record automatically, you stop paying the operations tax. Agents handle exceptions, not routine steps. Customers act where they already are. The ledger moves, and you can trace why, with evidence and audit trails that satisfy risk and compliance.
The last mile friction tax
Context switches are costly. A portal login, an app download, or a phone transfer adds time, error risk, and drop‑off at the exact moment a customer is ready to act. This friction compounds across thousands of invoices and accounts every month.
In‑message self‑service removes those obstacles. Customers verify identity with a one‑time code, see prefilled details, and choose only eligible actions. Inputs validate in real time, consent captures cleanly, and the success state is clear. The result writes back to core systems without anyone rekeying data.
This shift changes team dynamics. Queues shrink, exceptions are easier to spot, and audits stop chasing missing evidence. Leaders gain reliable numbers they can trust and improve. It feels calmer because the system does the routine work consistently, and people focus where judgment is needed.
What metrics should replace vanity counts?
Replace handle time, bot containment, and send volume with measures tied to outcomes. Completion rate shows how many tasks finish, time to resolution shows speed, writeback success proves data integrity, and deflection shows agent load avoided. These four combine into a clear picture of cost and quality.
Set simple pilot targets to detect early wins:
Completion rate: aim for a 10 to 20 percent uplift over baseline in 30 to 60 days.
Time to resolution: target a drop from days to hours for routine cases.
Writeback success: hold at 99 percent or higher with zero duplicates.
Deflection: move 40 to 70 percent of eligible cases out of agent queues.
For context on cash flow gains from better collections execution, see this overview of automated invoice collections and cash flow optimization.
The real bottleneck is the writeback contract, not the cadence
The writeback contract determines whether automation reduces work or adds rework. Define the fields that must change, the evidence required, and the error handling rules before you write copy or design screens. Cadence tweaks cannot fix a workflow that does not close the loop.
Define the writeback contract first
Start from the system of record. For each workflow, name the target tables or endpoints, the fields to update, and the exact states that mark success or failure. Specify what evidence must attach, like timestamped consent, documents, or identity checks. Map error codes to clear exception paths.
When this blueprint exists, everything else gets easier. Copy calls for one action, UI only shows eligible choices, and policy rules are testable. Ops can validate outcomes without engineering because the contract is explicit. Auditors see where evidence lives and how it ties to the update.
Do not skip idempotency keys and retry rules in this stage. They belong in the contract because they protect data integrity. Document how keys are created, how long they live, and what should happen after a timeout or partial failure. That clarity prevents duplicate posts and hidden drift.
After you have the schema and states documented, anchor design choices to that contract:
Success and failure states aligned to source‑of‑truth fields, not UI labels.
Evidence requirements listed by type, storage location, and retention window.
Exception routing that names owners, SLAs, and fallback actions.
Why idempotency prevents expensive mistakes
Duplicate posts and race conditions are silent and costly. They create reconciliation work, break customer trust, and can trigger compliance issues. Idempotent requests make each outcome apply only once, even if the same call retries due to a network hiccup or timeout.
Select keys that represent the business event, not a transient call. A payment authorization might use account ID plus a unique payment intent. A plan setup could use customer ID plus a schedule hash. The point is repeatability, so the system can tell a duplicate from a new action every time.
Retries with exponential backoff and circuit breakers add resilience without flooding brittle services. Combined with clear error handling, these patterns turn transient failures into eventual success or clean exceptions. For a broad look at how automation reduces error, review this note on medical billing automation and error reduction.
Integration handled for you reduces risk
Most failures live at the edges, not in the flow diagram. Legacy cores, SOAP endpoints, batch files, and mixed auth schemes hide the real work. When the communication layer owns adapters, schema mapping, credentials, telemetry, and writeback guarantees, pilots stop breaking on glue code.
This matters in regulated settings. Teams keep control of policy and outcomes while a managed layer handles connectivity and resilience. You cut time to value because the heavy lifting is in place. You also avoid the hidden cost of maintaining custom integrations across teams and releases.
If you prefer to minimize vendor sprawl, pick one platform that treats integration and writeback as first‑class work. That choice often prevents the misunderstood failure where a pilot looks fine in tests but fails under volume due to brittle edges. It is a practical way to reduce risk.
The hidden cost of skipping resolution first automated workflows
Skipping resolution first automated workflows adds time, cost, and risk that are easy to miss. Manual wrap‑up, rekeying, and reconciliation inflate unit cost even when message volume is high. Without closed‑loop telemetry, you cannot see where completion fails or why bad debt grows.
Quantify time to resolution and unit cost
Put numbers to the work. Start with one month of routine cases and track every handoff, from first outreach to final system update. Record agent touches, rework, and exceptions. Time adds up in minutes per case that scale to weeks of lost throughput for large books.
Translate those minutes into unit cost. Include agent time, supervisor escalations, and any manual reconciliation by back‑office teams. The aim is not perfection, it is a fair baseline. You need a before snapshot to judge a pilot and to set thresholds that guard against false positives.
Be strict about what counts as done. A processed payment or a plan posted in the system of record is complete. A note that says the customer plans to pay next week is not. This line keeps the math honest and makes wins visible when the loop actually closes.
To build a reliable baseline, document:
Start and end timestamps per case, plus every handoff in between.
Minutes spent on manual wrap‑up, rekeying, and reconciliation.
Percentage of outcomes with full evidence attached and searchable.
Where manual wrap‑up fails and creates rework
Manual wrap‑up breaks in predictable ways. Agents toggle between screens and miss a field. Notes vary by person and shift. Documents sit in inboxes without a link to the case. These misses create callbacks, repeats, and disputes that drag teams into an avoidable spiral.
Closed‑loop writebacks with digital consent and timestamped evidence kill this rework before it starts. Inputs validate at the point of entry. Evidence stores alongside the case. Outcomes update the source of truth in one shot. Exceptions route with full context so people can act, not rediscover.
If you track the misses, you will see the pattern. The same gaps appear week after week. They are not about effort or intent, they are about system design. Resolution inside the message fixes the root cause, then audits confirm the fix with less hunting.
Common failure modes to watch:
Rekeyed data that drifts from what customers provided.
Missing consent or documents that force an agent to call back.
Partial updates that leave flags, balances, or notes out of sync.
What leaders lose without closed-loop telemetry?
Without step‑level telemetry, leaders miss where drop‑offs happen. You cannot see retry storms, endpoint timeouts, or silent errors, and you cannot prove that a writeback posted cleanly. That blind spot hides risk, masks cost, and slows improvement.
Instrument every step: outreach send and delivery, link opens, identity checks, form submissions, payment calls, and writebacks. Store results in a way that supports both dashboards and audits. It is the simple path to spotting friction, fixing it, and showing impact in numbers that matter.
For a practical view on improving collections processes, this guide to automating collections steps highlights how visibility and standardization raise completion and reduce DSO. The same logic applies here: you cannot improve what you cannot see.
What it feels like to chase payments without a closed loop
Chasing payments without a closed loop feels like running in sand. Queues grow, scripts change, and nights stretch long, yet outcomes stall at the last mile. Customers try to act, hit a portal wall, and give up. The stress is real, and it is a system problem, not a people problem.
Night shifts, stalled queues, and customer fatigue
Teams rewrite copy, add shifts, and open new lines, but the work just moves, it does not finish. Customers receive more reminders yet still need to log in or wait on hold at the moment of action. That gap fuels fatigue on both sides and pushes even willing customers to delay.
Leaders feel the strain. Forecasts slip because simple cases drag into the week. Training improves consistency, but it cannot remove steps hardwired into the process. When a routine case always needs a person to close it, volume wins and people lose. It is exhausting, and it does not scale.
Resolution inside the message changes that day‑to‑day reality. The system completes routine cases, then shows you which exceptions need care. Nights get shorter, queues get lighter, and customers finish what they started. The mood shifts from firefighting to steady delivery.
Why careful teams still struggle despite best intentions?
You run a regulated operation. Caution is earned. The struggle comes from fragmented tools, not from lack of planning. When flows jump between channels and systems, even a well‑designed script turns into manual reconciliation and rework.
Low‑risk pilots offer a path out. Pick one policy‑bound use case with clear success states. Keep people in the loop for exceptions, but let the system handle the rest. Measure completion, speed, writeback success, and deflection. If those move in the right direction, scale one step at a time.
The goal is not a big bang. It is safer to earn trust with a small, auditable win. That approach respects your diligence and reduces risk. It also builds internal support because the gains are visible and the process is understandable.
How to build resolution first automated workflows that close the loop
You build resolution first automated workflows by defining the writeback and evidence first, then shaping outreach and in‑message steps to serve that contract. Keep actions channel‑native, validate inputs inline, and prove the pilot with outcome metrics before scaling. This sequence limits risk and raises completion.
Step 1: Map outcomes, evidence, and idempotency
Document the outcome blueprint before any creative work. Name the fields that change in the system of record, the legal or policy evidence required, and the success and failure states. Make idempotency a first‑class element, not an afterthought, with keys tied to business events.
Create a validation checklist operations can run without engineering. Include what to look for in logs, how to verify evidence attachments, and how to confirm that balances, flags, or notes updated correctly. This makes pilots testable in the way auditors and managers expect.
When things go wrong, make it easy to see and fix. Map specific error codes to next actions and owners. This keeps exceptions moving while the majority of cases resolve straight through.
Your outcome blueprint should include:
Target endpoints or tables, fields to update, and allowed state transitions.
Evidence list with type, storage location, and retention window.
Idempotency key format, retry rules, and how duplicates are detected.
Step 2: Orchestrate channel-native messaging
Design outreach that respects consent, timing windows, and channel preferences. Keep copy specific, show prefilled facts like amounts or dates, and point to a single action that opens the embedded mini‑app. The aim is action, not awareness.
Sequence nudges based on real responsiveness. If SMS works for one group and email for another, let the system adapt accordingly. Spread touches over a sane time window that reduces fatigue yet keeps momentum. Always make the next step clear.
Test messages like you test code. Measure opens, clicks, and completion, then tune copy and timing. Small changes in clarity or timing often unlock big gains in resolution.
Useful orchestrations often include:
One clear call to action with no competing links.
Dynamic templates that prefill known data to cut effort.
Cadence rules that stop nudges once completion posts.
Step 3: Design the in-message mini-app
Keep the mini‑app focused on the outcome. Show only eligible actions based on policy and context, validate inputs inline, and capture consent with a timestamp. Use progressive disclosure so customers see what they need when they need it.
Identity checks should fit risk and friction. One‑time codes or known‑fact validation often strike the right balance for billing and collections. For higher risk actions, step up to stronger checks without forcing a channel switch.
End with a clear success state. Tell customers exactly what changed and what happens next. That confirmation reduces calls and builds trust. It also aligns with your writeback contract so the evidence lives where auditors expect it.
Design elements to include:
Prefilled fields for known data, with inline validation on edits.
Consent capture with clear language and stored proof.
A simple success screen that confirms the update and next steps.
Step 4: Prove the pilot before scaling
Pick one high‑volume, policy‑bound use case. Define a sample size large enough to see movement and set stop‑or‑scale thresholds. Track completion uplift, time‑to‑resolution reduction, writeback success, and deflection. Keep the run between 30 and 60 days so the signal is clean.
Protect budgets by using go or no‑go gates. If completion or writeback success misses the threshold, pause and fix. If both hit, expand to the next workflow. This stepwise approach lowers risk and builds confidence with every release.
Share results in the language the business uses. Unit cost, cycle time, and risk reduction resonate across finance, operations, and compliance. That alignment speeds adoption and keeps everyone focused on outcomes, not features.
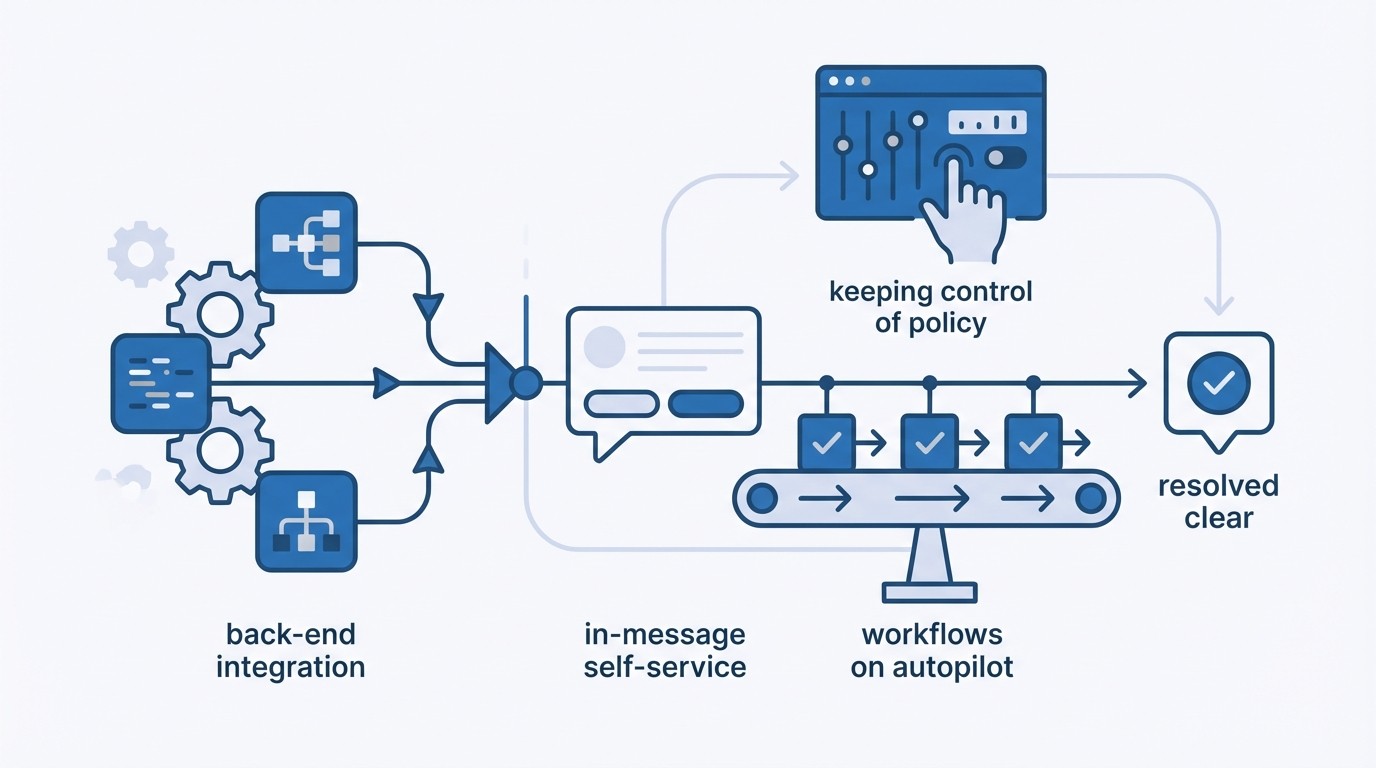
How RadMedia operationalizes resolution first automated workflows
RadMedia makes this approach practical by handling back‑end integration, delivering in‑message self‑service, and running workflows on autopilot with clear writebacks. You keep control of policy and outcomes while RadMedia operates the connective tissue that closes the loop safely.
Managed back-end integration with idempotent writebacks
RadMedia connects to REST and SOAP APIs, message queues, and SFTP. The team manages authentication, schema mapping, and error handling, then guarantees idempotent writebacks with retries and telemetry. That removes the brittle edges where most pilots fail at scale.
The impact ties directly to earlier costs. Automated, consistent writebacks cut manual wrap‑up minutes and reduce reconciliation. Clear error routing shrinks exception dwell time. Telemetry makes drop‑offs and retry storms visible so fixes are fast and fact based.
If your baseline showed drift between what customers submitted and what systems stored, this is where it stops. Idempotency keys align to business events, retries have rules, and every outcome either posts once or raises a clean exception with context.
Transformation callbacks you can expect:
Fewer duplicate or partial updates, which reduces rework and disputes.
Shorter time from customer action to posted outcome in the core.
Evidence and audit logs attached where risk and compliance expect them.
In-message self-service that drives completion
RadMedia’s secure, no‑download mini‑apps let customers update payment details, set plans, confirm identity, and upload documents inside the message. Identity checks match risk, inputs validate inline, and digital consent stores with timestamps. The success state is clear, and customers finish without a portal detour.
This deflects routine cases from agents and lowers unit cost. It also improves customer experience because there is no context switch at the moment of action. You get more completed tasks and fewer abandoned attempts.
Leaders gain consistency. The same steps run the same way every time, so training burden drops. Exceptions still escalate, but they arrive with full context so people can decide faster and better.
Autopilot orchestration and smart sequencing
RadMedia’s workflow engine links back‑end triggers to outreach and in‑message interactions. It executes rules, applies eligibility and policy, and escalates only exceptions with full context. Smart sequencing adapts channel and timing to prevent missed engagements and fatigue.
This is where your pilot metrics rise together. Completion goes up because customers act where they already are. Time to resolution falls because there are fewer handoffs. Deflection grows because routine work never hits the queue. For additional perspective on collections outcomes, see this note on automated collections email campaigns and reducing DSO.
RadMedia operates as a managed service, so your teams do not spend quarters wiring systems. You focus on policy and outcomes. The platform runs the loop that turns messages into posted results you can trust.
Conclusion
Resolution first automated workflows change the unit economics of billing and collections. Define the writeback and evidence first, remove last‑mile friction with in‑message self‑service, and prove the pilot with outcome metrics. When outcomes post automatically and exceptions carry context, you reduce cost and risk while customers finish the job.